Improving Llama 2 Performance by Overclocking Arrow Lake Intel Graphics

Improve Llama 2 generative AI performance by 40% at nearly no efficiency cost by overclocking the graphics cores and memory subsystem.
Introduction
In SkatterBencher #86 I illustrated how a 20% undervolt of the Intel Graphics integrated in the Core Ultra 9 285K reduced the reported Graphics Core power by 40% in the OCCT 3D Standard Stress Test.
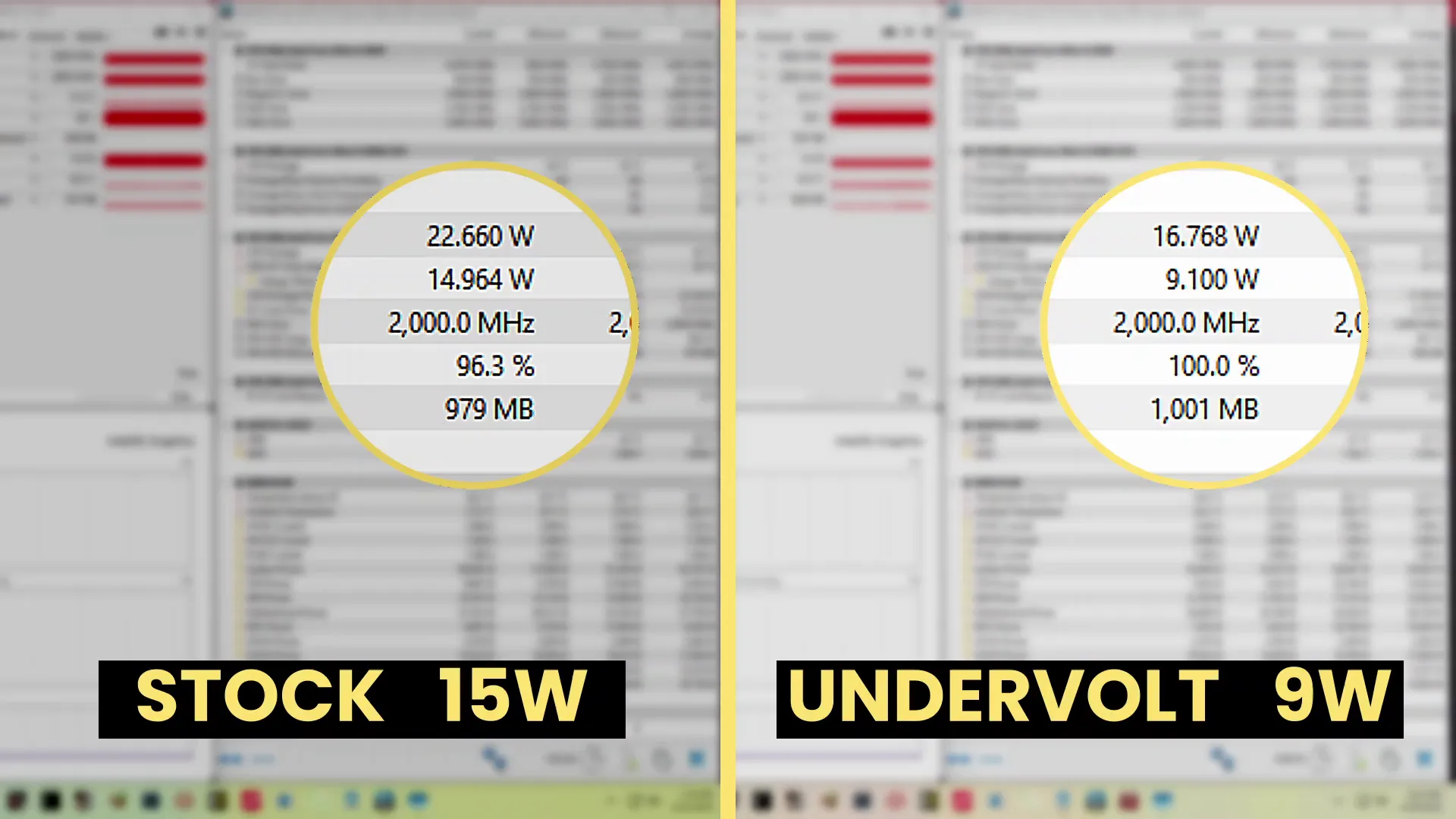
Today, I want to have a closer look at using the undervolting potential to improve the efficiency for Llama 2 generative AI workloads. For this purpose, I’ll rely on MLPerf Client – a relatively new benchmark I’ve been playing with.
MLPerf Client Llama 2 Benchmark
MLPerf Client is a benchmark developed by MLCommons to evaluate the machine learning (ML) performance of consumer-grade systems such as laptops, desktops, and workstations. It focuses specifically on large language model performance.
The first version, v0.5, was made available on December 11, 2024, with initial support for Intel integrated graphics. Just last month, MLCommons released an update to the benchmark, dubbed v0.6, with support for the Intel NPU – something Intel obviously liked very much.

The benchmark workload is based on Meta’s Llama 2 7B parameter LLMs. It’s optimized for reduced memory and computational requirements via 4-bit integer quantization. The benchmark supports Windows 11 and a range of AMD, Intel, and NVIDIA consumer hardware. MLPerf Client v0.6 is available now as a free download at mlcommons.org.
I like MLPerf Client a lot because it’s a great addition to the AI Benchmark I’ve been using in my SkatterBencher guides for a while now. Whereas AI Benchmark primarily tests perceptive AI performance, MLPerf Client adds to that with generative AI performance testing.
Measuring Llama Efficiency
When evaluating the energy efficiency of AI hardware, two key metrics often come up: performance per watt and joules per token. While they may sound similar, they measure different things.
Performance per watt tells us how much computational work a chip can deliver for each watt of power it consumes. That makes it a preferred metric for comparing the efficiency of hardware itself, regardless of the model being run.
On the other hand, joules per token measures how much total energy is required to process a single token, incorporating not just the chip’s performance, but also how the model (like Llama 2), memory access patterns, and system overhead affect energy consumption. While useful for understanding the cost of running AI models in production, it’s less ideal for isolating hardware performance since it’s influenced by model-specific factors.
Furthermore, we can choose different ways of measuring power consumption. We have three options: (a) graphics core power, (b) CPU package power, and (c) total system power.
The first two metrics we can measure using HWiNFO as they’re values calculated and reported by the Arrow Lake CPU power control unit. The third metric we can measure using the BENCHLAB – an ATX-sized PCB that sits between the motherboard and the power supply. Note that total system power doesn’t account for the power supply efficiency, but rather the power draw of the system components from the power supply.
With the Core Ultra 9 285K at default settings, the Intel Graphics generates 14.49 tokens per second while using 68.93W on average for a benchmark duration of about 15 minutes. That translates into 0.210 tokens per joule or 4.76 joule per token.
| Metric | Default |
| Frequency / Voltage | 2000 MHz at 0.978 V |
| Performance | 14.49 tokens / sec |
| GT Cores Power | 9.85 W |
| CPU Package Power | 19.65 W |
| System Power | 68.93 W |
| Performance / Watt (System) | 0.210 tokens / joule 4.76 joules / token |
Now we can have a look at the impact of overclocking and undervolting on AI workload efficiency.
Intel Graphics Undervolting & Overclocking
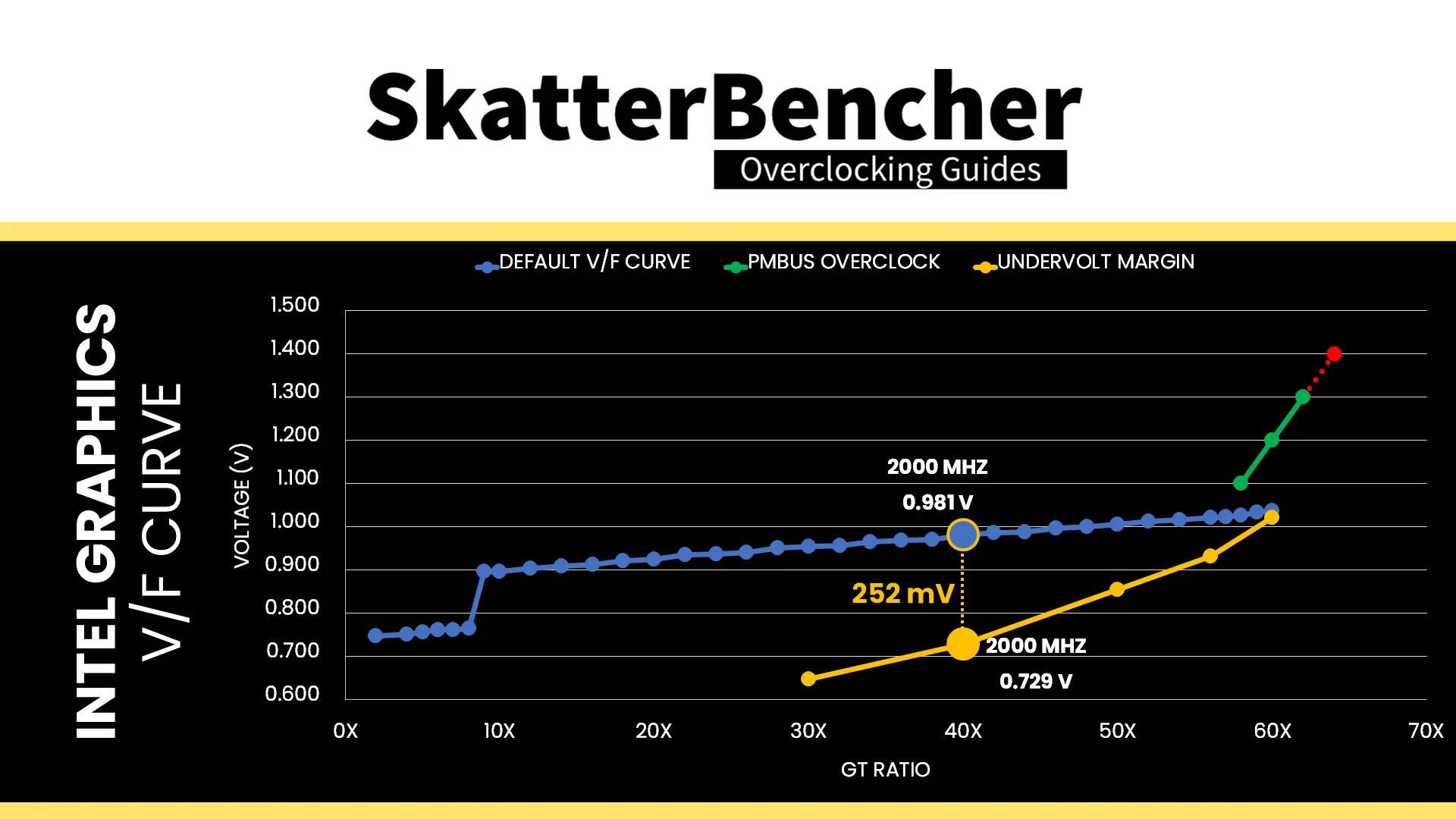
For this post, I ran two configurations: one overclocked to 2800 MHz and another undervolted by 20% at the default frequency of 2000 MHz. The overclocked configuration also has an increased operating voltage according to the standard voltage-frequency curve.
For more information on how to overclock and undervolt the Intel Graphics on Arrow Lake, I gladly refer you to SkatterBencher #86.
After undervolting the Intel Graphics, we obviously generate the same 14.49 tokens per second. However, power consumption reduces dramatically! The graphics cores power is now 5.76W instead of 9.85W which is a reduction of 41.5%. On a system level, the power reduction is not as much as it’s only reduced by 2.6W to 66.33W, a 3.8% reduction. That translates into 0.218 tokens per joule or 4.58 joule per token.
| Metric | Default | Undervolt |
| Frequency / Voltage | 2000 MHz at 0.978 V | 2000 MHz at 0.778 V |
| Performance | 14.49 tokens / sec | 14.49 tokens / sec |
| GT Cores Power | 9.85 W | 5.76 W |
| CPU Package Power | 19.65 W | 16.39 W |
| System Power | 68.93 W | 66.33 W |
| Performance / Watt (System) | 0.210 tokens / joule 4.76 joules / token | 0.218 tokens / joule 4.58 joules / token |
After overclocking the Intel Graphics by 40% to 2800 MHz, we generate 16.62 tokens per second. That’s a 14.7% performance improvement. While it doesn’t sound that amazing, bear in mind that the operating voltage only increased by 4.8% from 0.978 V to 1.025 V. The system power consumption increased to 74.98W, an increase of 8.8%. That translates into 0.222 tokens per joule or 4.51 joule per token, an efficiency improvement over default by 5.45%.
| Metric | Default | Undervolt | Overclock |
| Frequency / Voltage | 2000 MHz at 0.978 V | 2000 MHz at 0.778 V | 2800 MHz at 1.025 V |
| Performance | 14.49 tokens per sec | 14.49 tokens / sec | 16.62 tokens / sec |
| GT Cores Power | 9.85 W | 5.76 W | 13.37 W |
| CPU Package Power | 19.65 W | 16.39 W | 24.46 W |
| System Power | 68.93 W | 66.33 W | 74.98 W |
| Performance / Watt (System) | 0.210 tokens / joule 4.76s joule / token | 0.218 tokens / joule 4.58 joule / token | 0.222 tokens / joule 4.51 joules / token |
The result might be a surprise to some because, usually, overclocking doesn’t increase power efficiency. However, as I highlighted in SkatterBencher #86, the standard voltage-frequency curve is far from the most efficient as it uses more voltage than necessary. At 2800 MHz the curve is much more optimized, resulting in a better performance per watt.
Memory Subsystem Overclocking
Next, I also had a look at enabling Intel 200S Boost and tuning the memory timings. As I demonstrated in the SkatterBencher guide, tuning the memory subsystem has a sizeable impact on Intel Graphics performance.
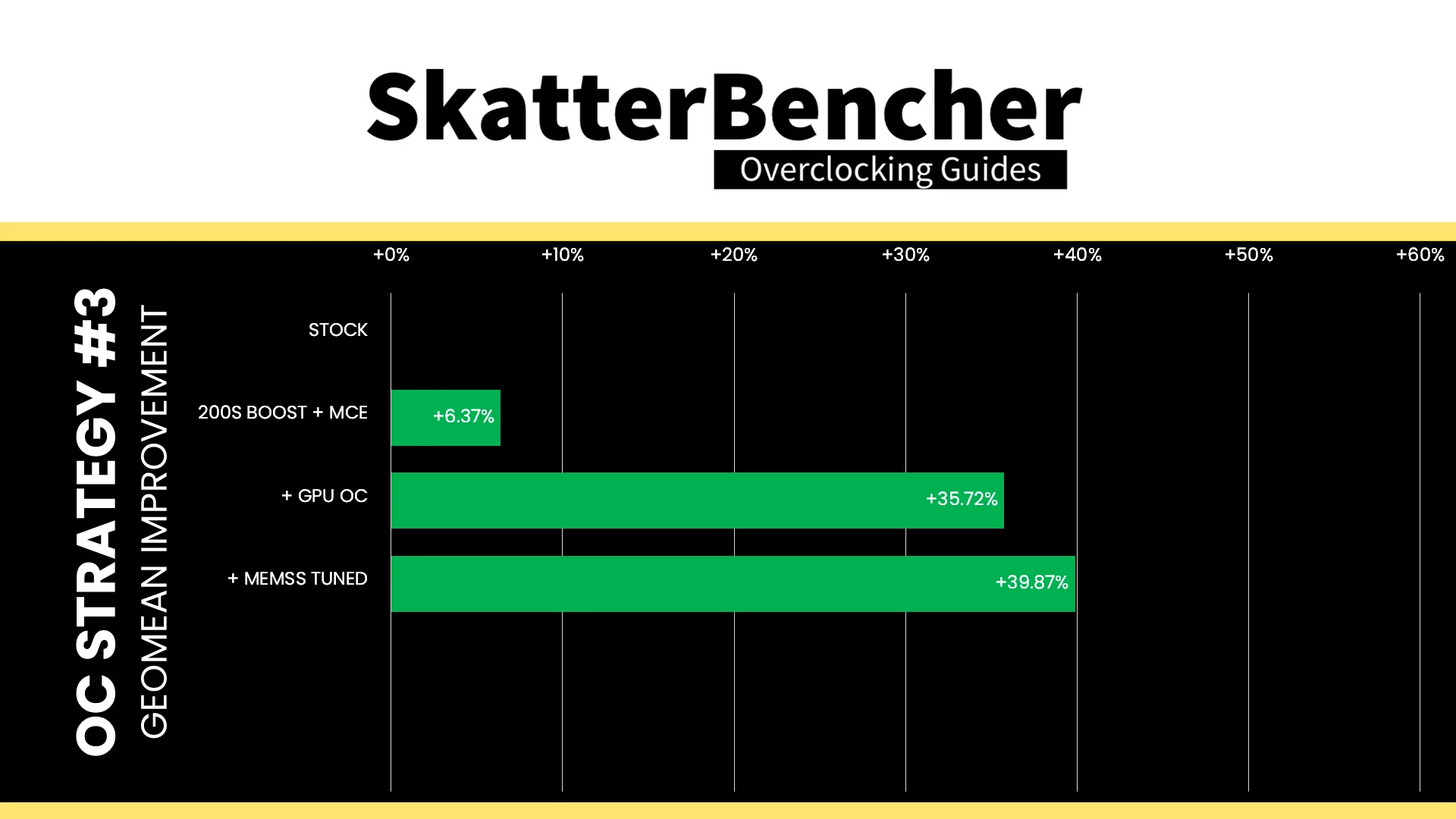
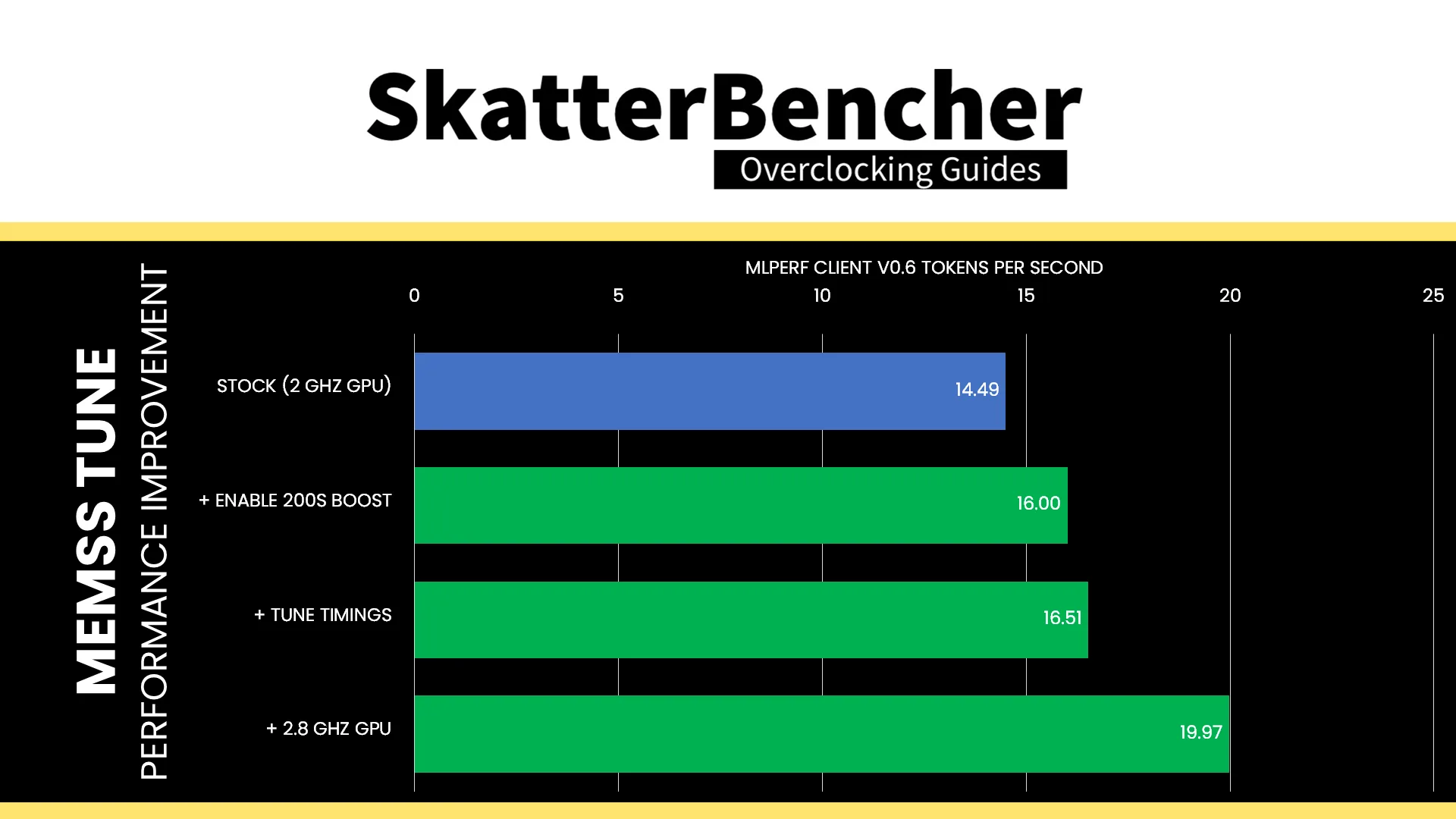
We see the same with MLPerf Client: enabling 200S Boost increases performance at default graphics frequency by 10.4% to 16.00 tokens per second. Tuning the memory timings further increases the performance to 16.51 tokens per second.
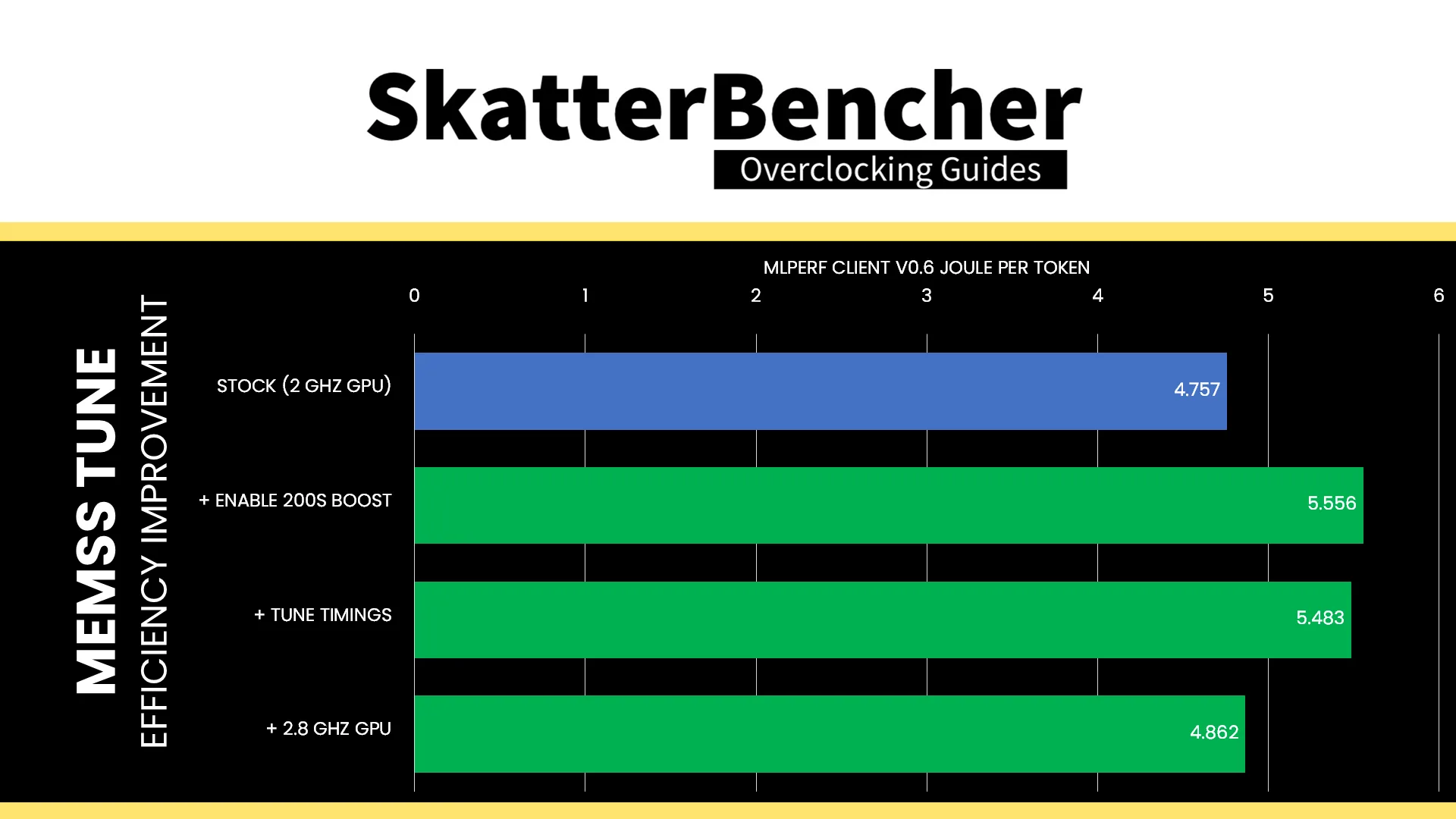
In terms of efficiency, however, the increase of System Agent to 1.2V and system memory voltage to 1.4V does more harm than good. Enabling 200S Boost decreases the efficiency by 14.39% from 4.76 joule per token to 5.56 joule per token. Tuning the memory timings improves it slightly to 5.48 joule per token. That makes sense because we’re effectively optimizing the memory performance without increasing the operating voltage.
So, this is a typical trade-off where we get lower efficiency in exchange for higher performance. We could try lower system agent and system memory voltages to claw back some of the power efficiency, however that’s for another blog post or enthusiast to try.
One thing we can try, however, is overclocking the Intel Graphics to 2800 MHz as we’ve seen can help improve efficiency. With overclocked Intel Graphics, 200S Boost enabled, and tuned memory timings, the performance improves by 37.8% to 19.97 tokens per second. The total system power is 97.10 watt, an increase of 40.9% over default, which yields 4.862 joule per token. That’s about 2% less efficient than stock but, of course, gives higher overall performance.
Outro
In my SkatterBencher guide I already highlighted that the default voltage-frequency curve of the Intel Graphics on Arrow Lake is far from ideal. That margin can be exploited to improve power efficiency in various applications.
In this post, I demonstrate that it’s possible to increase Llama 2 generative AI performance by almost 40% at nearly no efficiency cost by overclocking the graphics cores and memory subsystem. Similarly, you can improve power efficiency by about 4% by undervolting the graphics cores at default frequency.
Optimizing the memory subsystem will give you higher performance but the elevated voltages also push up power consumption. If you’re in need of just higher performance, that might be a trade-off you’re willing to make.
Alright, that’s it for this CheckPoint – let me know if you have any ideas in the comments below, and see you in the next one!